Goal
Set up a repeatable experiment to choose the best model for a customer-support summarization use case.Step 1: Define Evaluation Criteria
Use simple scoring dimensions:- Accuracy (0-5)
- Instruction adherence (0-5)
- Clarity/formatting (0-5)
- Response time (fast/medium/slow)
Step 2: Create Baseline Prompt
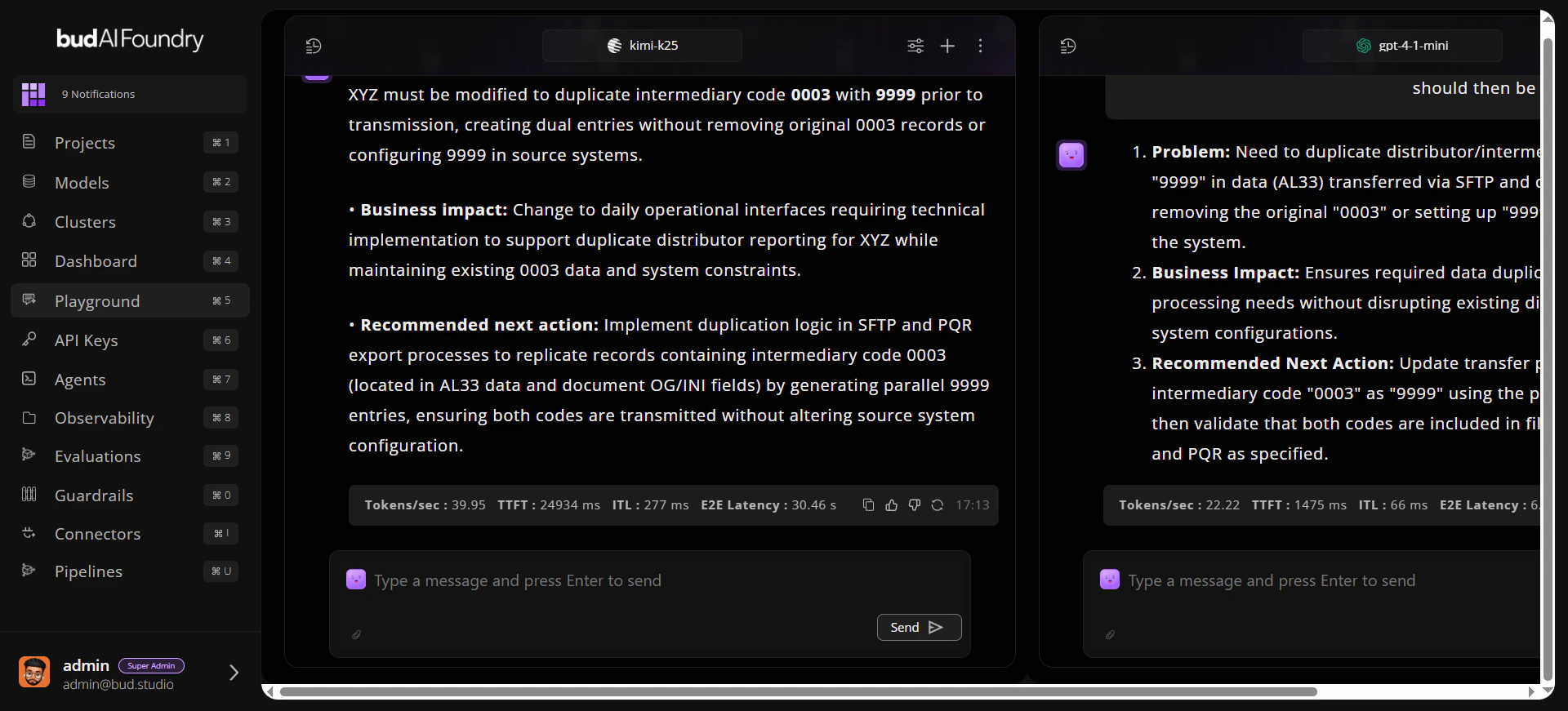
Example prompt:Step 3: Run Across Two Models
- Open two chat panes.
- Bind each pane to a different model.
- Send the same baseline prompt.
- Capture outputs and latency observations.
Step 4: Tune Parameters
Adjust one variable at a time:- Temperature
- Max response length
- Stop conditions
Step 5: Save the Winner
- Keep the best conversation in history.
- Note final prompt and parameter values.
- Share results with deployment owners before production rollout.
Expected Outcome
At the end of this workflow, you should have:- A validated prompt template
- A preferred model choice for the task
- Reproducible settings for follow-up testing