Benchmark workflow
What to measure
- Latency: response time characteristics for target traffic patterns.
- Throughput: sustained request handling capacity.
- Duration: total benchmark completion time.
- Consistency: result stability across reruns and environments.
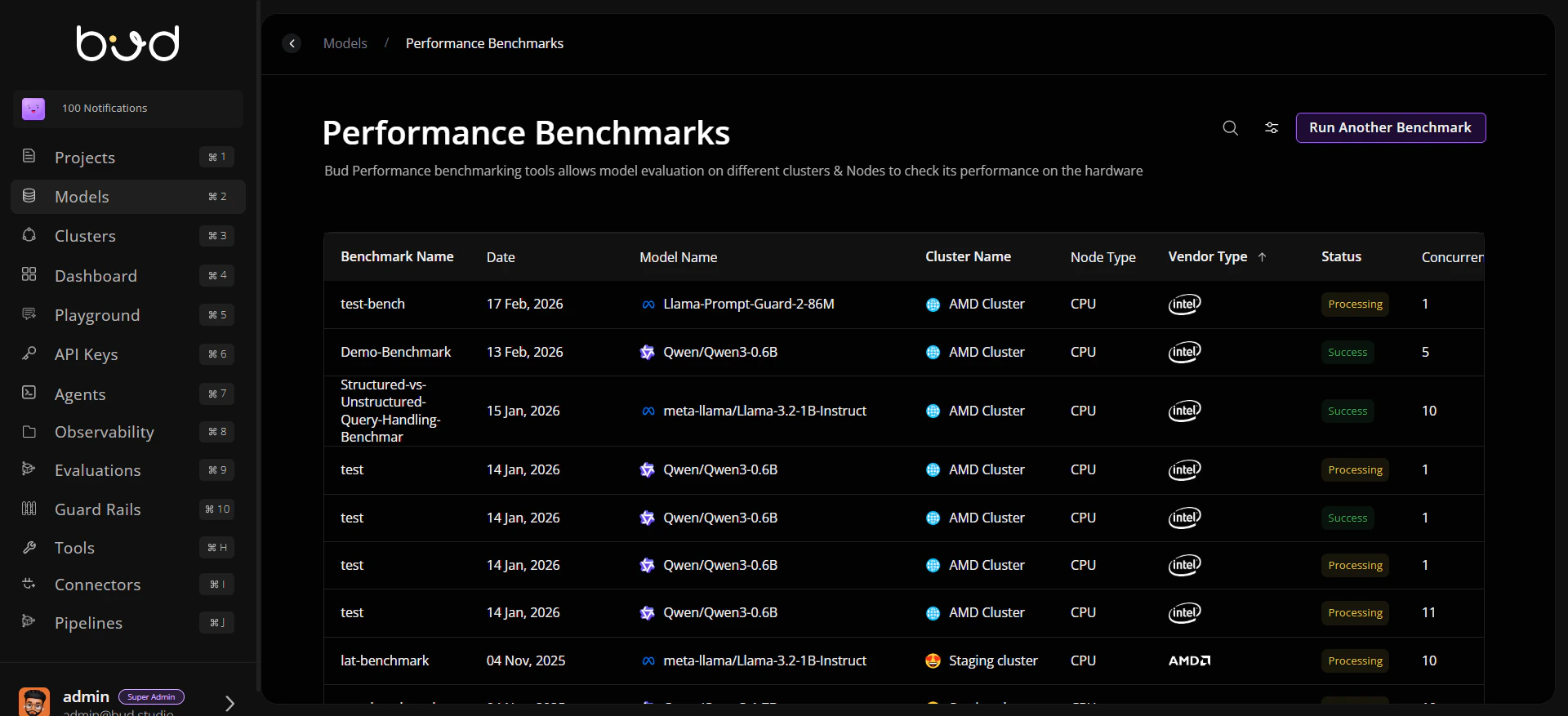
Demo walkthrough
- Open Benchmark History from the Models area.
- Click Run Another Benchmark.
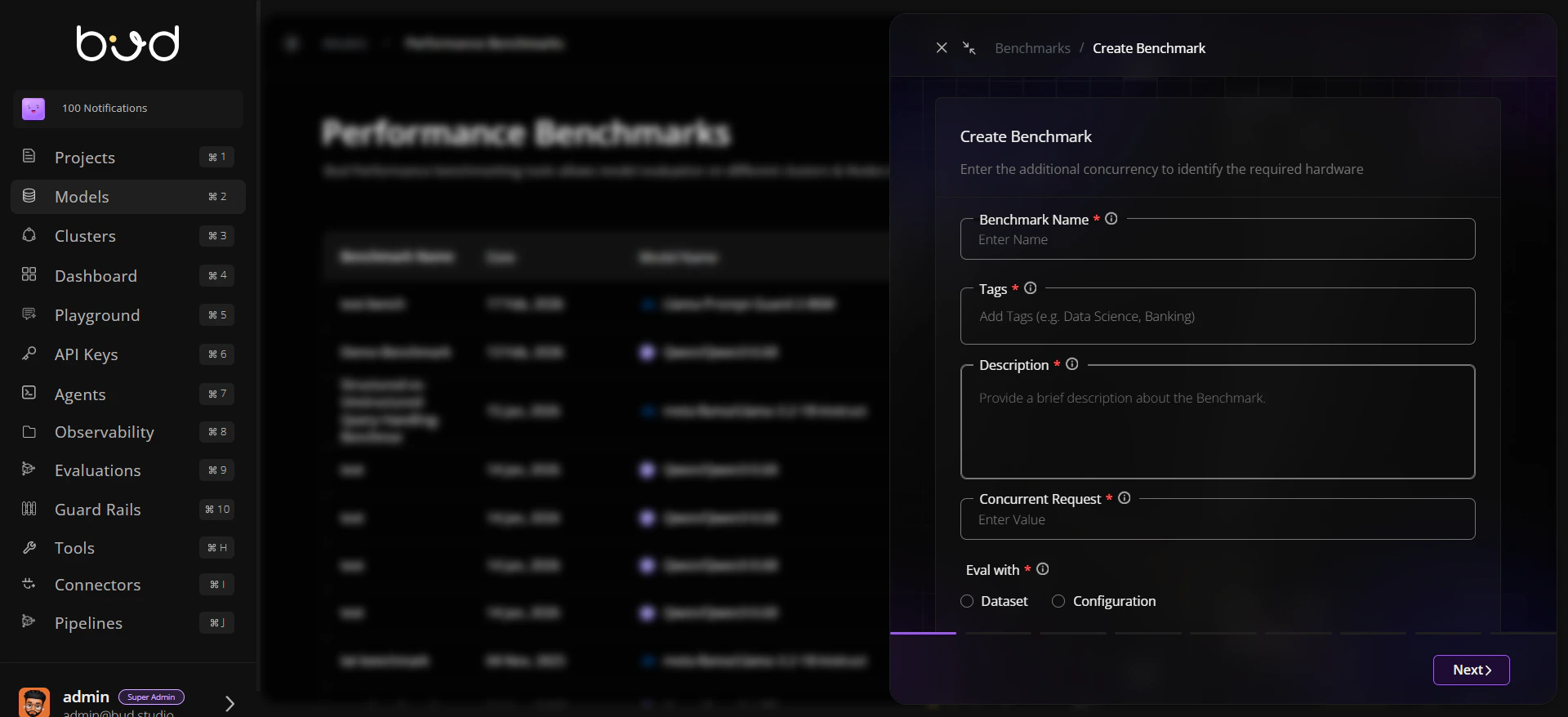
- Enter benchmark metadata (name, tags, description, concurrent requests).
- Choose evaluation mode:
- Dataset
- Configuration
- Select model, target cluster, and runtime settings.
- Run benchmark and monitor status.
- Review throughput, latency/TPOT, duration, and completion state.
Recommended process
- Start with 2-3 candidate models for the same workload.
- Run the same setup (dataset/config, hardware profile, concurrency) for fair comparison.
- Track benchmark history by model and status to identify regressions.
- Re-run critical scenarios after model, adapter, or infrastructure changes.
- Promote only configurations that satisfy performance SLOs.
Best practices
- Use descriptive benchmark names for easy audits.
- Tag runs by project, release, or use case for fast filtering.
- Separate exploratory runs from release-gating runs.
- Capture benchmark context (cluster type, runtime settings, request profile) with each run.
Escalation checklist
Latency and throughput meet service objectives.
Duration is acceptable for recurring validation cycles.
No regression versus the previous approved benchmark baseline.
Approval owner signs off promotion based on benchmark evidence.