Dynamic LoRA Loading for Agile AI
With dynamic LoRA loading, you can instantly load any number of LoRAs at runtime, adapting your models to various scenarios and tasks on the fly. This eliminates the need for redundant model deployments, boosting scalability and significantly reducing resource consumption.Optimize LLM Deployment and Costs
Our LoRA Model Adapter support is crucial for improving model density and dramatically reducing inference costs, especially for large language models (LLMs). By allowing dynamic loading and unloading of LoRA adapters, Bud Runtime makes it possible to deploy multiple models far more efficiently on shared infrastructure. This approach minimizes resource consumption by reusing base models across different tasks and simply swapping in lightweight LoRA adapters for specific tuning. The result is optimized GPU memory usage, faster cold start times, and enhanced scalability, making Bud Runtime ideal for high-density deployment and cost-effective inference in any production environment.How to Use
The below video shows how to use the multi-lora support in Bud Runtime.
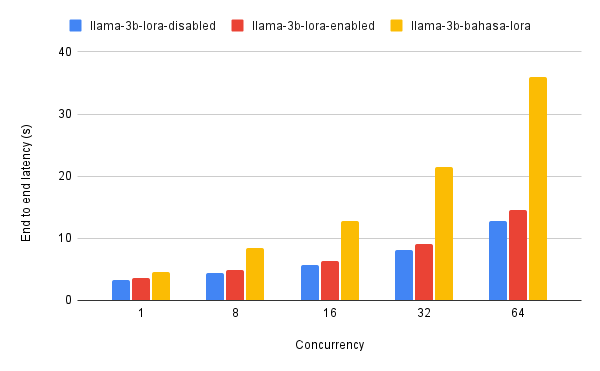
Performance
We have tested the performance of the multi-lora support in Bud Runtime and found that it is able to load and unload LoRA adapters in a matter of seconds, with minimal impact on the performance of the model. Below shows the end-to-end latency of the multi-lora support running on a Nvidia V100 GPU.