> ## Documentation Index
> Fetch the complete documentation index at: https://docs.budecosystem.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Cluster Operations
> Run day-2 operations for health, deployments, and lifecycle management
## Overview
After onboarding, operators use Clusters for continuous health management, deployment oversight, and safe lifecycle changes.
## Daily Operations Loop
```mermaid theme={null}
flowchart TD
A[Review Cluster Health] --> B[Inspect Deployments]
B --> C[Check Node Events]
C --> D[Tune Capacity or Settings]
D --> E[Document and Audit Changes]
E --> A
```
## 1) Health Monitoring
* Review **General** tab for CPU/GPU/memory/storage trends.
* Check for abrupt drops in available workers or nodes.
* Use time windows to detect regressions.
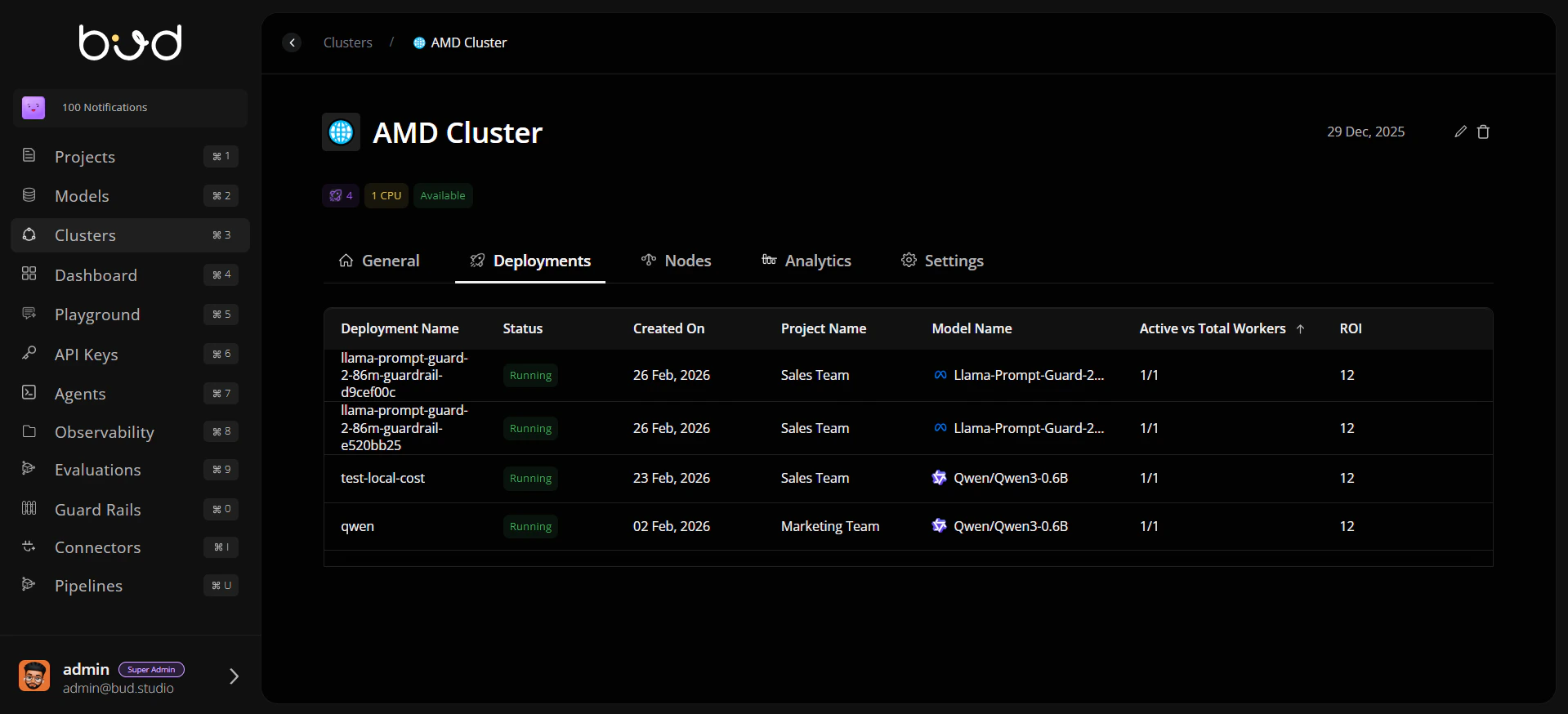
## 2) Deployment Oversight
* Open **Deployments** tab to review active workloads.
* Confirm deployment status, worker counts, and routing behavior.
* Escalate unhealthy deployments before cluster-wide degradation.
 ## 3) Node Diagnostics
* Use **Nodes** tab for request-vs-allocatable analysis.
* Open node event panels for warnings (scheduling failures, connectivity, taints).
* Prioritize repeated or high-severity events for immediate remediation.
## 4) Safe Editing and Deletion
* Use edit actions to update metadata like name or ingress.
* Before deletion, confirm no active endpoints depend on the cluster.
* Record change rationale for governance and post-incident reviews.
## Incident Response Pattern
```mermaid theme={null}
flowchart LR
A[Alert Triggered] --> B[Open Cluster General]
B --> C[Correlate with Deployments]
C --> D[Inspect Node Events]
D --> E[Mitigate: Reschedule, Scale, or Roll Back]
E --> F[Verify Recovery]
```
## Best Practices
Separate production and non-production clusters with clear naming.
Review node events before and after major deployment rollouts.
Avoid destructive operations during unresolved incidents.
Align cluster actions with RBAC and audit policy requirements.
## 3) Node Diagnostics
* Use **Nodes** tab for request-vs-allocatable analysis.
* Open node event panels for warnings (scheduling failures, connectivity, taints).
* Prioritize repeated or high-severity events for immediate remediation.
## 4) Safe Editing and Deletion
* Use edit actions to update metadata like name or ingress.
* Before deletion, confirm no active endpoints depend on the cluster.
* Record change rationale for governance and post-incident reviews.
## Incident Response Pattern
```mermaid theme={null}
flowchart LR
A[Alert Triggered] --> B[Open Cluster General]
B --> C[Correlate with Deployments]
C --> D[Inspect Node Events]
D --> E[Mitigate: Reschedule, Scale, or Roll Back]
E --> F[Verify Recovery]
```
## Best Practices
Separate production and non-production clusters with clear naming.
Review node events before and after major deployment rollouts.
Avoid destructive operations during unresolved incidents.
Align cluster actions with RBAC and audit policy requirements.